Advertisement
Working with data can feel a bit like stepping into a foreign country. There are strange file types, inconsistent formats, and a lot of hidden quirks. But if you're just starting in Python and trying to make sense of all that data, Pandas is your best travel companion. It's not flashy or overly complicated — it's a toolkit built to help you make sense of raw information in a way that feels grounded and practical.
When you're dealing with data in different formats, such as CSV, Excel, JSON, or SQL, knowing how to wrangle each of them with Pandas is essential. This article walks you through how to work with different data formats in Pandas without getting lost in the details.
When you’re starting off, one of the first hurdles is seeing just how flexible Pandas is. Whether you’re handed a .csv file, an Excel spreadsheet, or a JSON dump, Pandas can handle it — with the right function. The most common starting point is usually the CSV file. It’s plain text and widely used. You can load it into a DataFrame with one line of code: pd.read_csv('filename.csv'). But there’s more to this than just reading files.
Each file type has its structure. Excel files might contain multiple sheets, each with a different layout. Pandas lets you specify a sheet or load them all into a dictionary of DataFrames. JSON is more hierarchical and often nested, so reading it cleanly might require flattening parts of it using normalization functions. SQL databases use tables and queries, but Pandas still handles them with read_sql_query() or read_sql_table() if you have a connection ready.
Pandas doesn’t just open files—it reads them with context. If your CSV uses semicolons instead of commas, Pandas lets you set that. If your Excel file has merged cells or headers across rows, you can skip rows or rename columns as needed. Beginners often assume loading data is a one-step process. But in practice, you’re always adjusting how that data gets read.
Once you’ve managed to read in a file, that’s not the end of the story. In fact, it’s just the beginning. Most datasets — even the official ones — come with noise. You’ll often run into missing values, inconsistent column names, or data types that don’t match. This is where the real work begins.
Pandas shine in these early cleanup stages. Functions like dropna(), fillna(), and astype() give you quick ways to handle missing data, fill in blanks with defaults, or convert columns from text to numbers. If your CSV has a date column that’s been read as a string, you can convert it to proper datetime format using pd.to_datetime(). This is crucial because working with dates as strings prevents you from performing calculations such as time differences or resampling over time.
You also need to pay attention to column headers. Sometimes, the first row of your data isn't actually the header. You can specify the header row when reading the file or set column names manually after loading it in. Sometimes, the dataset comes with duplicate rows, extra whitespaces, or rows that serve no analytical purpose — Pandas lets you strip these out efficiently.
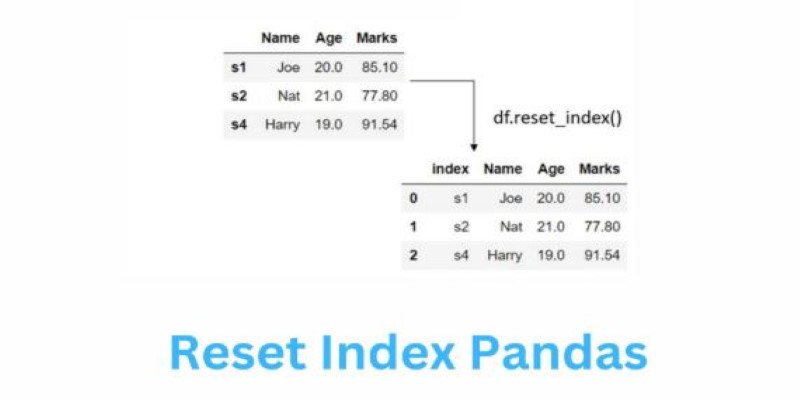
Another common issue is data alignment. Especially in Excel files, values can be off by a row or a column, or rows can have inconsistent lengths. Using reset_index(), set_index(), and slicing techniques can help bring uniformity. At this stage, the focus is on getting your data into a format where each row represents a single observation, and each column is a specific attribute. This tidy format is what Pandas works best with.
Once your data is cleaned up and you’ve done your analysis or transformations, you often need to save or share the results. Pandas makes this step just as accessible as reading files. The most common function for this is to_csv(), which allows you to save your DataFrame as a CSV file. But it goes much further.
Want to export an Excel file? Use to_excel(). Need to save as JSON for a web project? to_json() has you covered. If you're working with a database, to_sql() allows you to write your DataFrame back to an SQL table — a very useful step when integrating Python with larger data pipelines.
But exporting is not just about writing files. You often need to format things. You may want to drop index values when exporting to CSV or include them when saving to Excel. You may want to compress the file, encode it in UTF-8, or limit it to selected columns. Pandas give you these options, which means you control how clean and precise your exported file is.
A lesser-known tip for beginners: you can export multiple sheets into a single Excel workbook using the ExcelWriter context manager. This is handy if you’re summarizing different slices of a dataset and want to share them all in one file. Each function in Pandas, while intuitive, often has depth — and exploring its options is what takes you from beginner to confident practitioner.
One of the key lessons when working with different file formats is the value of a consistent data workflow. You don’t want to redo your process every time you switch from JSON to SQL or Excel to CSV. Pandas supports a pipeline approach: read → clean → transform → export.

No matter the data source, your workflow can mostly stay the same. Start by understanding the data’s structure, then clean and reshape it for your analysis. Finally, save the results in the format that fits the next step — whether that’s sharing with a colleague, feeding a machine learning model, or archiving.
This mindset — abstracting the format and focusing on structure — saves time and reduces frustration. It also prepares you for working with live data feeds, APIs, or larger datasets. As you keep using Pandas, you’ll find it’s less about memorizing every function and more about knowing when and how to use them. That confidence builds with experience.
Pandas make data handling approachable for beginners. Rather than memorizing every function, focus on practicing the process: import, clean, structure, and export. Each file format is different, but Pandas helps you adapt. As your confidence grows, handling data becomes second nature. You won't worry about the file type—you'll understand how to work with it. With steady practice, Pandas become a dependable part of your data toolkit.
Is Claude 2 the AI chatbot upgrade users have been waiting for? Discover what makes this new tool different, smarter, and more focused than ChatGPT.

How Enterprise AI is transforming how large businesses operate by connecting data, systems, and people across departments for smarter decisions

How the ONNX model format simplifies AI model conversion, making it easier to move between frameworks and deploy across platforms with speed and consistency

Explore the key differences between Frequentist vs Bayesian Statistics in data science. Learn how these two approaches impact modeling, estimation, and real-world decision-making

Compare Excel and Power BI in terms of data handling, reporting, collaboration, and usability to find out which tool is better suited for decision making
How Fetch cuts ML processing latency by 50% using Amazon Sage-Maker and Hugging Face, optimizing inference with async endpoints and Hugging Face Transformers

Swin Transformers are reshaping computer vision by combining the strengths of CNNs and Transformers. Learn how they work, where they excel, and why they matter in modern AI
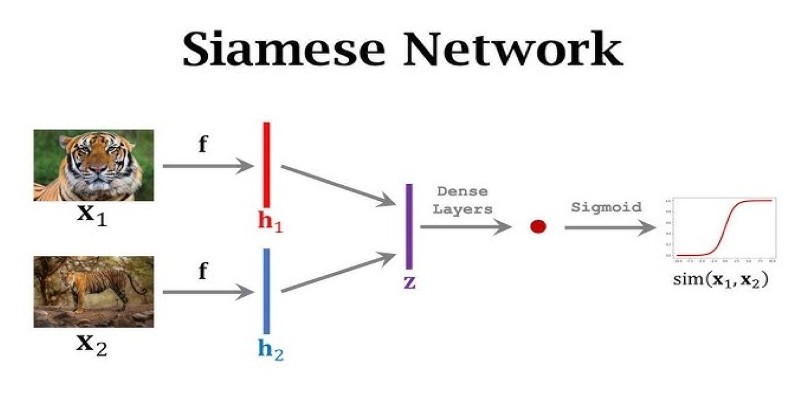
What makes Siamese networks so effective in comparison tasks? Dive into the mechanics, strengths, and real-world use cases that define this powerful neural network architecture

What data management is, why it matters, the different types involved, and how the data lifecycle plays a role in keeping business information accurate and usable

Discover the top 8 most isolated places on Earth in 2024. Learn about these remote locations and their unique characteristics

How fine-tuning Llama 2 70B using PyTorch FSDP makes training large language models more efficient with fewer GPUs. A practical guide for working with massive models
Explore how GPTBot, OpenAI’s official web crawler, is reshaping AI model training by collecting public web data with transparency and consent in mind