Advertisement
Fine-tuning a 70 billion parameter model isn’t simple. Llama 2 70B is huge, and handling it takes careful setup. Standard training tools fall short at this scale, mainly due to memory limits and slow throughput. That’s where PyTorch FSDP helps. It shatters the model across GPUs, so no single device holds the full model.
This makes it possible to fine-tune Llama 2 70B without needing a massive GPU cluster. If you need your version of Llama 2 for specific tasks or domains, FSDP gives you a practical path—without cutting corners on what the model can learn.
PyTorch’s Fully Sharded Data Parallel works differently from older approaches. Instead of replicating the entire model on each GPU, FSDP splits it into shards. Each GPU holds a portion of the model and handles only that piece during forward and backward passes. This drastically lowers memory use per device.
It also shards gradients and optimizer states. That’s important—states for optimizers like AdamW can take more memory than the model itself. Sharding them lets you work with large models on setups that would otherwise fail due to memory errors.
FSDP supports mixed precision training, too. Using bfloat16 or fp16 reduces memory even more and speeds up training. Combined with PyTorch’s AMP, this makes it easier to keep the model stable without using full precision.
Another feature that helps with large models is sharded checkpointing. FSDP saves the model in pieces, one per GPU rank. This cuts down checkpoint size and speeds up recovery when restarting. By using state_dict_type="sharded", you save and load only what each GPU needs.
Wrapping the model for FSDP needs care. Don’t just wrap everything at once. Use Auto-Wrap Policy or manually apply FSDP to transformer blocks. This gives better performance and avoids slowdowns caused by poor load balancing across GPUs.
Start with Meta’s gated release of Llama 2 70B. Once you have access, load the model using Hugging Face Transformers. Make sure your environment is ready. You’ll need at least 8 A100 80GB GPUs for full fine-tuning, but with FSDP, you can push the limit and go lower.

Set up FSDP using wrap() and Auto-Wrap Policy. Target the transformer layers and leave embedding layers unwrapped when possible. Keep memory usage low by running dry passes and profiling early.
Use mixed precision with torch.cuda.amp to reduce overhead. Most of the training benefits from lower precision without affecting output. In many cases, bfloat16 is preferred due to its wider range.
Train using gradient accumulation. You won’t be able to fit large batches on one GPU, so accumulate steps to simulate bigger batch sizes. Tune micro_batch_size and gradient_accumulation_steps until training is stable.
Be selective with logging. Llama 2 70B takes time to show progress, and logging every step can slow you down. Evaluate less frequently, checkpoints less often, and monitor training with care.
For your dataset, stick with a format that matches Llama’s pre-training. If you're doing instruction tuning or domain adaptation, format your data accordingly. Make sure the tokenizer and prompts are aligned with the base model.
Fine-tuning Llama 2 70B takes time and patience. Even with FSDP, the iteration speed is slower than in smaller models. Changes in loss or accuracy don't show up quickly, so trust your process and avoid overfitting to early feedback.
Watch for load imbalance. Some layers might slow down training due to uneven computation. Use torch.profiler to spot lagging parts and adjust your wrapping strategy to improve performance.
Monitor memory and time per step. Small missteps—like overwrapping layers or skipping mixed precision—can lead to large slowdowns. Adjust settings gradually and rerun dry passes after any major change.
If you’re adapting the model for a specific domain, test it often on downstream examples. Waiting until the end to check model behavior can cost days of computing. Use a validation set with real-world examples from your domain and check response quality along the way.
Checkpoint is often enough to protect against crashes but not so often that it eats up disk space. With FSDP, you can save smaller shards, which helps reduce overhead during saving.
Using FSDP also means you can scale up later. Start with fewer GPUs, and if your training gets better results, add more devices. FSDP will adapt—this flexibility is hard to match in other setups.
FSDP fine-tuning makes it possible to work with models you’d normally avoid due to size. Instead of using adapter methods like LoRA, you can change the full model. That’s important for tasks where the base model doesn’t behave quite right or lacks context for your data.

It's not frictionless. Debugging is harder when the model is sharded. Errors may appear only on certain ranks, and syncing logs across devices can be tricky. Training takes longer per step, and setup requires a deeper understanding of PyTorch internals.
Still, the tradeoff is usually worth it. You get access to the full model’s capacity. You can fine-tune for style, domain, or task-specific formats with full flexibility. And you’re not locked into any one tool or API—FSDP runs within standard PyTorch.
This setup is also future-proof. As larger models become available, the same approach can scale. FSDP is flexible enough to support experimental model designs and memory-heavy training patterns without major rewrites.
Fine-tuning Llama 2 70B using PyTorch FSDP gives you access to a scale of model that once felt off-limits. With careful setup and the right hardware, you can modify the model end-to-end, adjusting it for your needs without shortcuts. FSDP handles the tough parts—memory, sharding, checkpointing—so you can focus on what the model is learning. It’s not just about squeezing a large model into limited hardware. It’s about opening up full-model training to more people, more use cases, and more creative possibilities. With the tools available now, that kind of work is no longer reserved for labs.

Discover the top ten tallest waterfalls in the world, each offering unique natural beauty and immense height

Can AI bridge decades of legacy code with modern languages? Explore how IBM’s generative AI is converting COBOL into Java—and what it means for enterprise tech

How Rocket Money x Hugging Face are scaling volatile ML models in production with versioning, retraining, and Hugging Face's Inference API to manage real-world complexity

How the ONNX model format simplifies AI model conversion, making it easier to move between frameworks and deploy across platforms with speed and consistency

How AI in real estate is transforming property search, pricing, and investment decisions. Learn how automation and predictive tools are streamlining the industry for buyers, agents, and investors

Learn the clear difference between data science and machine learning, how they intersect, and where they differ in purpose, tools, workflows, and careers

Compare Excel and Power BI in terms of data handling, reporting, collaboration, and usability to find out which tool is better suited for decision making

How AI in food service is transforming restaurant operations, from faster kitchens to personalized ordering and better inventory management
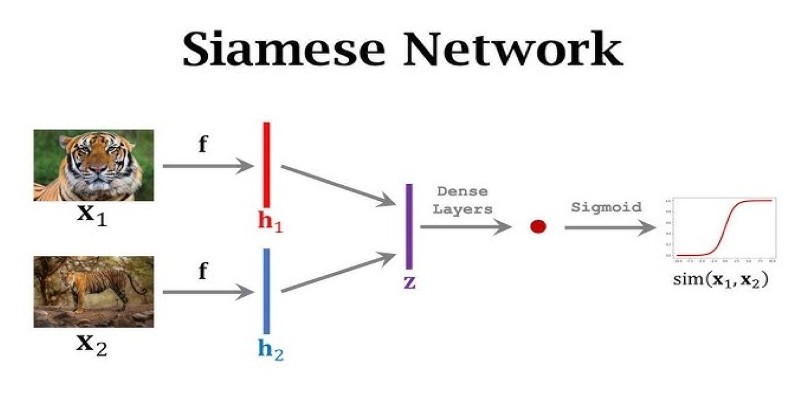
What makes Siamese networks so effective in comparison tasks? Dive into the mechanics, strengths, and real-world use cases that define this powerful neural network architecture
Explore how GPTBot, OpenAI’s official web crawler, is reshaping AI model training by collecting public web data with transparency and consent in mind

How GANs are revolutionizing fashion by generating high-quality design images, aiding trend forecasting, e-commerce visuals, and creative innovation in the industry
Explore the most unforgettable moments when influencers lost their cool lives. From epic fails to unexpected outbursts, dive into the drama of livestream mishaps