Advertisement
When working with datasets on Huggingface, most developers end up using print statements or manually inspecting a few samples. This is fine for small datasets, but the moment you start working with large collections of samples, especially for training or debugging models, it gets tedious. You scroll through chunks of text or image references and still feel like you're missing patterns. This is where interactive exploration changes the game.
The idea is simple: view your data in a way that lets you search, filter, and understand it better—without writing long chunks of code. And yes, it’s possible with just one line, thanks to the integration of visualization tools built to handle Huggingface datasets directly. Let’s look at what that one line actually does and why it can make a real difference in how you work.
Working with a dataset isn’t just about loading it and training a model. You need to understand the structure, spot inconsistencies, and check edge cases. Interactive tools let you do that faster and with more clarity.

For example, if you’re working on a classification task, it’s helpful to scroll through labeled samples, look at class distributions, and even search by a specific label. If you’re working with translation or summarization datasets, being able to instantly compare source and target texts side by side is a big help. And when it comes to images or audio, the ability to preview files right there in your browser changes everything. Instead of writing filtering logic or debugging print loops, you’re clicking, scrolling, and typing inside a search bar. It’s smoother, quicker, and honestly, more enjoyable.
Here’s what the line looks like:
python
CopyEdit
ds.push_to_hub("my-dataset", private=True); from datasets import load_dataset; from huggingface_hub import notebook_login; notebook_login(); from datasets.viewer import show; show(load_dataset("my-dataset"))
Looks like a mouthful? Let’s break it down.
1. ds.push_to_hub("my-dataset", private=True)
This line uploads your dataset (loaded in ds) to your Huggingface account. Setting private=True keeps it visible only to you. If your dataset is already on the hub, you can skip this.
2. from datasets, import load_dataset
This just ensures that you can fetch any dataset from Huggingface.
3. from huggingface_hub import notebook_login; notebook_login()
You’ll need to log in to your Huggingface account to access or upload datasets. This command pops up a token box—paste your token, and you're in.
4. from datasets.viewer import show; show(load_dataset("my-dataset"))
This is the heart of it. The show() function opens up an interactive UI right inside your notebook (or in a new browser tab, depending on your setup). You get filters, search boxes, and scrollable previews—all tied to your dataset.
Once it opens, here’s what you’ll notice:
There’s usually a sidebar that shows you every field in your dataset—text, labels, IDs, whatever’s in there. You can pick a field and filter by it. For text, that means searching for keywords. For labels, it means choosing specific categories. It’s especially helpful when you need to spot class imbalances or check how consistently a label is used.
Scroll through your dataset with arrow keys, or just flick through with your mouse. You'll see one row at a time, expanded. If it's text, it's rendered cleanly. If it's an image, it displays the actual image. Audio? It gives you a play button. You can quickly catch formatting issues, encoding problems, or fields that didn’t map correctly during preprocessing.
Each example shows up with all the metadata intact. If your dataset has tokens, tags, or source references, everything is displayed neatly in the same pane. It’s easier to spot if something’s missing or looks off. You can also compare related fields side by side, which helps during error analysis.
The search bar at the top supports simple queries like finding all samples containing a keyword or matching a specific label. It works across columns, so if you want to find samples where the source is in French and the label is “news,” you can do that without extra code. This is a huge time-saver during dataset reviews or when fixing mislabeled entries.
Interactive exploration only works well if your dataset is formatted properly. That doesn’t mean jumping through hoops, but it does mean being consistent.
Avoid using spaces or special characters in column names. Stick to lowercase letters and underscores. The viewer tool uses these names as headers and for filtering.
The viewer works best with text, images, audio, and simple lists or dictionaries. If you have nested structures or custom objects, you’ll run into issues. Convert them to supported types before uploading.

If your dataset is huge (think millions of rows), the interactive viewer may take time to load or crash. Consider slicing a smaller version for exploration and keeping the full set for training.
If you’re working with a dataset split into train/validation/test, load only one split at a time when exploring. You can still switch between them easily by calling show(load_dataset("my-dataset", split="test")).
One line of code might not sound like much, but in this case, it brings up a full-featured, clean, and interactive interface that makes data work smoother. Instead of getting stuck scrolling through raw data or building visualization scripts, you get instant access to search, filtering, and preview features.
Whether you’re prepping for training or checking edge cases post-training, interactive exploration with Huggingface’s built-in tools saves time and helps you build more confidence. All without leaving your notebook. Stay tuned for more informative yet interesting guides.

Explore the range of quantization schemes natively supported in Hugging Face Transformers and how they improve model speed and efficiency across backends like Optimum Intel, ONNX, and PyTorch

How Würstchen uses a compressed latent space to deliver fast diffusion for image generation, reducing compute while keeping quality high
Explore the most unforgettable moments when influencers lost their cool lives. From epic fails to unexpected outbursts, dive into the drama of livestream mishaps

Discover five engaging and creative methods to teach your kids about saving money and instill essential financial literacy skills

What data management is, why it matters, the different types involved, and how the data lifecycle plays a role in keeping business information accurate and usable

How GANs are revolutionizing fashion by generating high-quality design images, aiding trend forecasting, e-commerce visuals, and creative innovation in the industry

Compare Excel and Power BI in terms of data handling, reporting, collaboration, and usability to find out which tool is better suited for decision making

Can AI bridge decades of legacy code with modern languages? Explore how IBM’s generative AI is converting COBOL into Java—and what it means for enterprise tech

Nvidia's Perfusion method redefines AI image personalization with efficient, non-destructive customization. Learn how this breakthrough approach enables targeted learning without model degradation
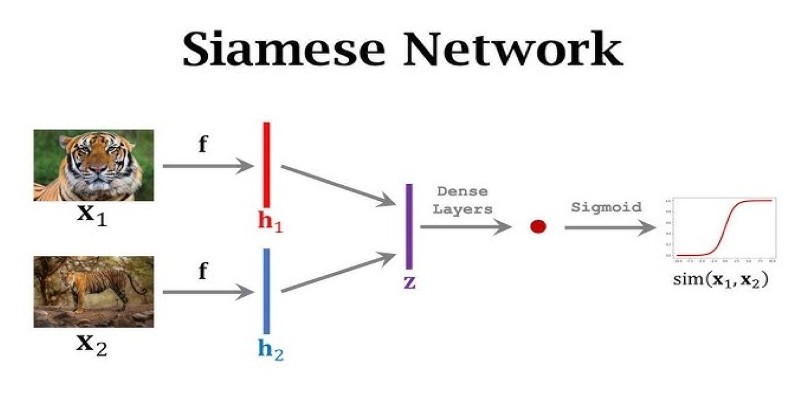
What makes Siamese networks so effective in comparison tasks? Dive into the mechanics, strengths, and real-world use cases that define this powerful neural network architecture

How the ONNX model format simplifies AI model conversion, making it easier to move between frameworks and deploy across platforms with speed and consistency

Discover the best places to see the Northern Lights in 2024. Our guide covers top locations and tips for witnessing this natural spectacle