Advertisement
Artificial intelligence is evolving at an incredible pace, and deep learning sits at the core of many breakthroughs. Among the lesser-known yet incredibly powerful architectures in this space is the Siamese network. This isn’t just another neural network—it’s a structure specifically designed to understand similarity.
Imagine an algorithm that can tell whether two photos show the same person, even if the lighting or angle differs. That's the practical charm of Siamese networks. They’re not just about classification or prediction—they excel at comparison. This article aims to walk you through the heart of Siamese networks: what they are, why they matter, and how they work in the real world.
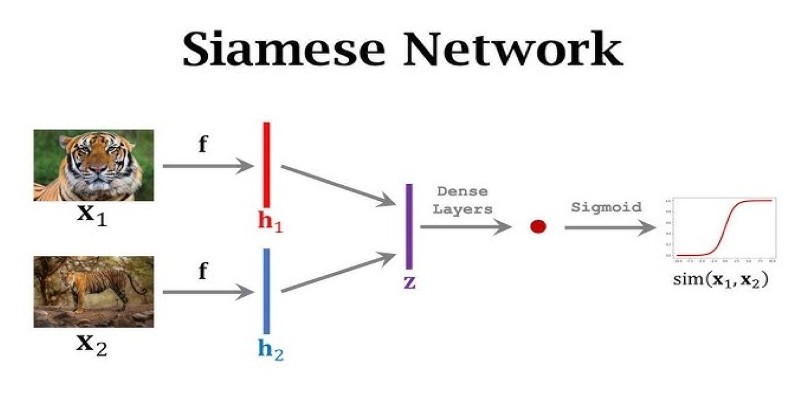
At its core, a Siamese network is a type of neural network architecture that learns to differentiate between two inputs. The idea is simple but powerful: you pass two data points through twin networks that share the same parameters. These twin networks then generate embeddings—compressed representations of the input—and the system calculates how similar those embeddings are.
Instead of classifying individual inputs like a typical neural network, Siamese networks focus on the relationship between inputs. Are they the same or different? Do they match or not? This makes them particularly useful in applications where identifying whether two things belong to the same category is more important than identifying the category itself. Think facial verification, signature matching, or identifying duplicate product listings.
The magic lies in the weight-sharing design. Both sub-networks are identical, ensuring they learn to encode the input data in the same way. That symmetry makes the network better at comparing features across different inputs, even if the raw data varies in quality, size, or noise level.
To understand how Siamese networks actually function, let's break down the typical architecture. Two inputs are fed into two identical subnetworks. These could be convolutional neural networks (CNNs) if you're working with images or recurrent networks for sequence data. These subnetworks produce a feature vector (embedding) for each input.
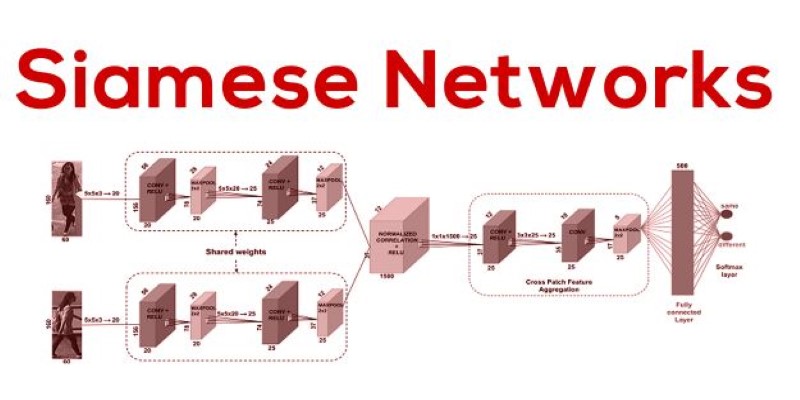
The distance between these two vectors—often calculated using Euclidean distance or cosine similarity—determines the level of similarity between the inputs. The smaller the distance, the more similar the inputs are deemed to be. During training, the network learns to minimize this distance for similar pairs and maximize it for dissimilar ones.
This learning process usually employs a contrastive loss function or a triplet loss. In the contrastive loss, the network is fed pairs of inputs along with a binary label indicating whether they are similar or not. The loss function encourages the embeddings of similar items to move closer together and those of dissimilar items to move farther apart. Triplet loss, on the other hand, involves an anchor input, a positive input (similar), and a negative input (dissimilar), aiming to ensure the anchor is closer to the positive than to the negative.
A real-world example helps illustrate this well. Suppose you’re building a facial verification system. You would train your Siamese network on pairs of face images. If both images are of the same person, the network should learn to produce embeddings that are very close in vector space. If the images show different people, the embeddings should be far apart. Once trained, the network can compare new image pairs in the same way, even if it has never seen those exact faces before.
Siamese networks are widely used across several domains, especially where comparing or verifying inputs is more valuable than classifying them outright.
One prominent use is facial recognition, particularly in “one-shot” learning scenarios. Traditional models need thousands of images to classify effectively, but Siamese networks can learn from just one or two examples. Once trained, they can verify whether a new face matches a known one with high accuracy, even if that face hasn't been seen before.
Another domain is signature verification. Financial institutions often need to check if a handwritten signature matches a reference on file. Siamese networks are well-suited here because they compare the structure and flow of pen strokes rather than classifying handwriting styles.
They’re also used to identify duplicate questions on Q&A platforms. On sites like Stack Overflow or Quora, users often ask similar questions in different words. A Siamese network can tell whether two questions are semantically equivalent, helping reduce redundancy and improve organization.
In medical imaging, they help detect whether two scans—like MRIs or X-rays—show the same condition or anomaly. This supports doctors in tracking disease progression or finding similar cases more easily.
A major strength of Siamese networks is their efficiency in data-scarce environments. Since they learn relationships rather than fixed categories, they don’t need large amounts of labeled data. This is useful for smaller datasets or rare cases.
They’re also adaptable. Though they began in image-based tasks, the core idea applies to text, audio, and sensor data. As long as data can be represented as vectors, the network can measure similarity effectively.
No model is without flaws, and Siamese networks are no exception. Their performance heavily depends on the quality of embeddings. If the feature extractor—the base network—doesn’t do a good job of representing the input data, the similarity measures become unreliable.

Training Siamese networks also requires careful selection of data pairs. Simply choosing random positive and negative pairs often leads to slow or suboptimal training. Hard-negative mining—where the model is specifically fed with negative pairs that are difficult to distinguish—is often necessary to improve performance.
Another challenge is scalability. While Siamese networks excel in one-on-one comparisons, they don't scale as naturally for large-scale classification tasks, where assigning inputs to a predefined number of categories is required. They are better suited to verification or retrieval tasks rather than full classification pipelines.
It's also important to note that training such models can be computationally expensive, especially with complex input types, such as high-resolution images or long text sequences. The need for multiple passes through paired inputs essentially doubles the workload during training.
Despite these challenges, the unique architecture and versatility of Siamese networks make them a compelling choice for many machine-learning problems where understanding similarity is crucial.
Siamese networks specialize in comparing pairs—focusing on similarity rather than classification. With twin networks sharing weights and utilizing embeddings for comparison, they're ideal for tasks such as face verification, text similarity, and image matching. Their strength lies in detecting subtle differences or likenesses. While not suited for every problem, when applied appropriately, they bring strong performance to tasks where understanding relationships between inputs is more important than labeling them.

Can AI bridge decades of legacy code with modern languages? Explore how IBM’s generative AI is converting COBOL into Java—and what it means for enterprise tech

Discover five engaging and creative methods to teach your kids about saving money and instill essential financial literacy skills
Is Claude 2 the AI chatbot upgrade users have been waiting for? Discover what makes this new tool different, smarter, and more focused than ChatGPT.

How fine-tuning Llama 2 70B using PyTorch FSDP makes training large language models more efficient with fewer GPUs. A practical guide for working with massive models

Swin Transformers are reshaping computer vision by combining the strengths of CNNs and Transformers. Learn how they work, where they excel, and why they matter in modern AI
What makes Siamese networks so effective in comparison tasks? Dive into the mechanics, strengths, and real-world use cases that define this powerful neural network architecture

How Rocket Money x Hugging Face are scaling volatile ML models in production with versioning, retraining, and Hugging Face's Inference API to manage real-world complexity

Explore the differences between the least populated countries and the most populated ones. Discover unique insights and statistics about global population distribution

How AI in real estate is transforming property search, pricing, and investment decisions. Learn how automation and predictive tools are streamlining the industry for buyers, agents, and investors

New to data in Python? Learn how to read, clean, and export CSV, Excel, JSON, and SQL formats using Pandas. A practical guide for beginners navigating real-world datasets

Discover the top 8 most isolated places on Earth in 2024. Learn about these remote locations and their unique characteristics

Nvidia's Perfusion method redefines AI image personalization with efficient, non-destructive customization. Learn how this breakthrough approach enables targeted learning without model degradation