Advertisement
When companies train and run machine learning models, speed isn't just a nice to have—it shapes how quickly teams can launch features, answer questions, and ship updates. Fetch, a consumer-rewards app with tens of millions of users, has been quietly working on ways to trim down the time it takes to process ML workloads.
The company recently slashed its ML inference latency by 50%, and the tools that made it possible weren’t exotic or complex. They used Amazon SageMaker, paired with Hugging Face’s open-source models and tooling. What they achieved isn't just about speed—it's about using existing tools more efficiently.
Before the shift, Fetch faced the same challenge many high-throughput platforms deal with: scaling up inference without runaway costs or lag. Their ML stack powers real-time receipt processing, which involves parsing, classifying, and extracting data from user uploads at a massive scale. This task relies on transformer-based models from Hugging Face, which, while accurate, aren't lightweight.
Every millisecond matters when you’re processing hundreds of millions of requests. The latency wasn’t just a tech issue—it had ripple effects across operations, impacting how quickly users received feedback and rewards. The engineering team at Fetch began looking for ways to cut down model serving times without rewriting the whole stack.
SageMaker provided an early advantage. Fetch was already using it to manage their training jobs and deploy models. What changed was how they used it. They shifted toward SageMaker’s new inference features that allow for better optimization and scaling behavior, including asynchronous inference and Multi-Model Endpoints (MME). These weren’t just features—they were tools to reduce idle time and increase throughput.
Fetch models were mostly built on Hugging Face Transformers, which gave them access to pre-trained models for tasks like token classification and document parsing. These models were hosted on SageMaker, and initially, everything ran synchronously: a user submits a receipt, the model processes it, and a response is returned in real-time.

That worked fine—until it didn’t. Latency crept up under load. So, Fetch switched to asynchronous inference using SageMaker. This approach doesn’t return results instantly. Instead, it lets models handle inference requests in batches, behind the scenes, and then send results when ready. For a user, this looks the same, but the backend has time to breathe. Models can process more data in one go, reducing the total number of spin-ups and idle compute time.
But that was only part of the story. Fetch also began using Multi-Model Endpoints. Rather than deploy one model per endpoint—which is compute-intensive and expensive—they stored multiple models on a single SageMaker instance. The endpoint loads the appropriate model on demand only when needed. This setup dramatically reduced cold start times and kept hardware use efficient.
To push it further, Fetch optimized their Hugging Face models using SageMaker's built-in support for Deep Learning Containers. These containers are pre-configured to work with Hugging Face libraries and include support for inference acceleration. They experimented with model quantization, reducing the model size without affecting accuracy much. This step alone cut processing time further, and more importantly, it slashed memory use—letting each instance do more work.
In real-world testing, these optimizations worked. Fetch observed up to 50% reduction in average ML processing latency. That translated into a better user experience and a smoother rewards process. The load on infrastructure dropped, meaning fewer computing resources were needed for the same volume of traffic.
This kind of reduction doesn’t come free. There were tradeoffs. Asynchronous inference means responses aren’t technically real-time, though for their use case, the lag was small enough not to matter. Multi-Model Endpoints added complexity in model versioning and management. But these were manageable changes—well worth the latency gains.
Using Amazon SageMaker with Hugging Face didn’t require deep internal tooling changes. That was a key benefit. The team avoided the need to switch to another framework or rewrite models. Hugging Face’s integration with SageMaker has matured enough that optimization steps like quantization, model compilation with optimum, and endpoint tuning are accessible without needing to build everything from scratch.
As part of their workflow, Fetch engineers leaned on SageMaker Pipelines for deployment automation. This helped them ship updates faster and test model changes across multiple environments before pushing live. The combination of scalable infrastructure and flexible model management allowed them to tune for latency and cost—a hard balance to strike.
Fetch's results show how much is possible with the right tools, even if you're not a tech giant. ML teams often assume that dramatic latency improvements require moving to custom inference servers or designing bespoke runtimes. But much of what Fetch did was available out of the box through Amazon SageMaker and Hugging Face's well-integrated ecosystem.

For teams running ML models at high volume, the Fetch case suggests a few priorities: adopt asynchronous serving when real-time responses aren't needed, use Multi-Model Endpoints to consolidate deployments, and make use of quantization and container-based optimizations to shrink the model size.
Hugging Face’s Transformers library remains central to their setup. Its compatibility with SageMaker made this process far smoother. Fetch didn’t need to switch to smaller architectures or abandon their preferred model types. Instead, they tuned the infrastructure and deployment mechanics around those models and saw real gains.
With user traffic expected to grow, Fetch now has a foundation that can scale without added latency. They’ll keep iterating, but the results so far show what’s possible when infrastructure decisions are made with both engineering simplicity and performance in mind.
Cutting ML processing latency by half is tough, but Fetch managed it without major code changes. Using SageMaker and Hugging Face features, such as async inference, Multi-Model Endpoints, quantization, and containerized deployment, they reduced both time and cost while maintaining accuracy. These tools are accessible and effective. For ML teams working at scale, Fetch shows that serving models smarter can deliver big performance gains without overhauling your entire stack.

Deploy models easily and manage costs with the Hugging Face Hub on the AWS Marketplace. Streamline usage and pay with your AWS account with-out separate billing setups

Discover five engaging and creative methods to teach your kids about saving money and instill essential financial literacy skills

Discover the best places to see the Northern Lights in 2024. Our guide covers top locations and tips for witnessing this natural spectacle

Compare Excel and Power BI in terms of data handling, reporting, collaboration, and usability to find out which tool is better suited for decision making
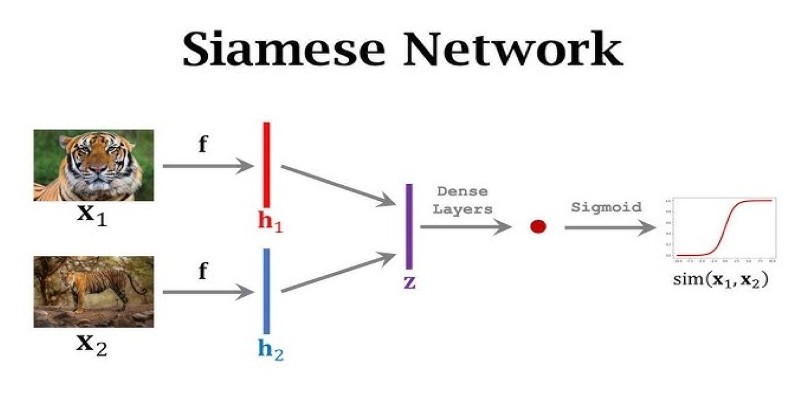
What makes Siamese networks so effective in comparison tasks? Dive into the mechanics, strengths, and real-world use cases that define this powerful neural network architecture

How fine-tuning Llama 2 70B using PyTorch FSDP makes training large language models more efficient with fewer GPUs. A practical guide for working with massive models

How Rocket Money x Hugging Face are scaling volatile ML models in production with versioning, retraining, and Hugging Face's Inference API to manage real-world complexity

Explore the differences between the least populated countries and the most populated ones. Discover unique insights and statistics about global population distribution

How to use transformers in Python for efficient PDF summarization. Discover practical tools and methods to extract and summarize information from lengthy PDF files with ease
Is Claude 2 the AI chatbot upgrade users have been waiting for? Discover what makes this new tool different, smarter, and more focused than ChatGPT.

How the ONNX model format simplifies AI model conversion, making it easier to move between frameworks and deploy across platforms with speed and consistency

Learn the clear difference between data science and machine learning, how they intersect, and where they differ in purpose, tools, workflows, and careers