Advertisement
Every business, app, or online interaction today runs on data — from tracking customer preferences to managing supply chains. But having lots of information isn't the same as using it well. That's where data management comes in. It's the behind-the-scenes work that keeps information useful rather than overwhelming. Without a plan, data becomes messy, hard to trust, and even more challenging to act upon.
With a good system, it becomes an asset — something that guides decisions saves time, and avoids costly mistakes. Whether you're running a startup or a large organization, managing your data properly isn't extra — it's part of staying effective, secure, and ready to grow.
Data management is the process of collecting, storing, organizing, and using data so that it stays accurate and available. It spans various methods, tools, and policies designed to treat information as a resource instead of just background noise. Each part of this process supports the next, creating a clear path from raw data to practical results.
Data storage is the first layer. This includes databases, cloud platforms, or data lakes where information is held and organized. Without secure and flexible storage, nothing else works well.
Data governance adds structure by defining how data should be used, who can access it, and how it's protected. It's especially important in areas like finance, healthcare, or government, where regulations around privacy are strict.
Data integration brings information from different sources together into a single view. This is common when businesses use different systems for sales, support, and inventory. Integration helps combine these into one usable dataset.
Another key area is data quality management. It ensures that the data is complete, consistent, and correct. Dirty data — such as outdated records or duplicates — leads to poor decisions.
Metadata management helps track what the data is about — who created it, when, and what it relates to. This is useful when organizing large data systems where context is needed.
Master data management creates a single, clear version of the most important data entities, such as customers or products. It avoids confusion that comes from having multiple records for the same thing.
Each of these plays a different role, but they all support the larger goal of keeping data clear, reliable, and ready to use.
The importance of data management has grown as the volume and variety of data have exploded. We now deal with both structured information, such as transaction logs, and unstructured content, like videos or social media comments. Without solid data handling, this flood becomes more of a burden than a benefit.

Good data management prevents waste — both time and money. It stops duplication, reduces errors, and makes it easier for different teams to use the same information. When people rely on the same data, decisions tend to be more consistent and grounded.
It's also about risk. Data breaches and leaks can lead to major legal and financial trouble. The mismanagement doesn't just look bad — it breaks trust. Systems with clear rules and access controls can protect against this. Encryption, audit trails, and user permissions are all tools that support secure data management.
Privacy regulations, such as GDPR or HIPAA, make strong data governance non-negotiable. Organizations must know what data they collect, how it's stored, and who has access. Failure to meet those standards can mean heavy penalties.
There's a practical side, too. When data is well-managed, it's easier to adapt to change. Whether it's adding a new tool, shifting to remote work, or responding to market shifts, reliable data speeds up the process. It also supports long-term projects, such as trend analysis, forecasting, and AI applications.
Strong data practices are what allow organizations to move from guesswork to informed decisions. Without it, analysis breaks down, and people go back to relying on gut feeling or outdated reports.
Data has a clear lifecycle — from creation to deletion — and each stage requires attention. It starts with data collection, where information is generated by user actions, systems, or external sources. If poor data enters here, it carries problems into every following step.

Next is storage, where data is saved either locally or on cloud platforms. How it’s stored affects how easily it can be accessed later. If storage systems are messy or outdated, retrieving the right data becomes slow and frustrating.
Then comes organization and maintenance. This stage involves tagging, indexing, and cleaning data. It removes duplicates, fixes errors, and ensures consistency. Without this, even well-stored data won’t be reliable.
The usage phase is where data supports real work. Reports are generated, trends are analyzed, and decisions are made. Whether it’s customer service, logistics, or strategic planning, this is the point where value is realized.
The final stage is archival or deletion. Keeping data forever is neither practical nor safe. Some information needs to be archived securely for future use, while other data should be deleted once it’s no longer needed. This reduces clutter, saves storage costs, and supports compliance with data regulations.
Each part of the data lifecycle depends on the others. If something goes wrong in one step, it can affect everything after it. That’s why managing the lifecycle carefully is a core part of overall data management.
Data doesn’t manage itself. Every click, scan, or input adds something new, but without structure, it builds up in ways that can’t be used. Data management is how we keep it useful. From accurate collection to secure storage and smart usage, every part of the process matters. It helps people work better, systems run smoother, and organizations make stronger decisions. By managing data well, businesses can focus on what the information tells them — not how to find or fix it. With the right approach, data becomes a reliable guide rather than a constant obstacle.
How Fetch cuts ML processing latency by 50% using Amazon Sage-Maker and Hugging Face, optimizing inference with async endpoints and Hugging Face Transformers

Discover the top ten tallest waterfalls in the world, each offering unique natural beauty and immense height

How the ONNX model format simplifies AI model conversion, making it easier to move between frameworks and deploy across platforms with speed and consistency
Is Claude 2 the AI chatbot upgrade users have been waiting for? Discover what makes this new tool different, smarter, and more focused than ChatGPT.

What data management is, why it matters, the different types involved, and how the data lifecycle plays a role in keeping business information accurate and usable
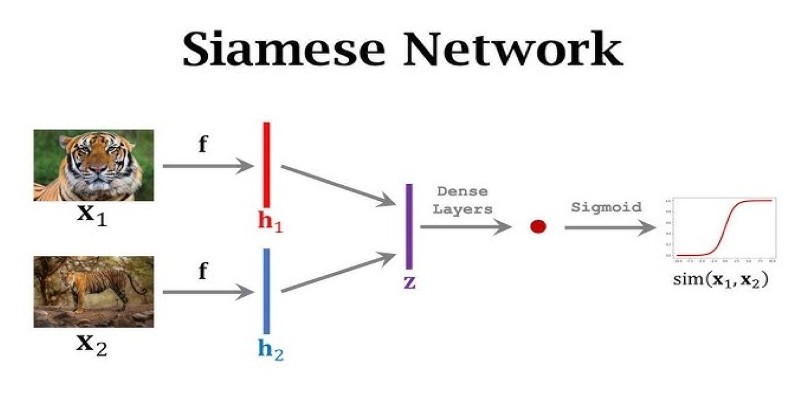
What makes Siamese networks so effective in comparison tasks? Dive into the mechanics, strengths, and real-world use cases that define this powerful neural network architecture

Learn the clear difference between data science and machine learning, how they intersect, and where they differ in purpose, tools, workflows, and careers

How AI in food service is transforming restaurant operations, from faster kitchens to personalized ordering and better inventory management

How fine-tuning Llama 2 70B using PyTorch FSDP makes training large language models more efficient with fewer GPUs. A practical guide for working with massive models

How Rocket Money x Hugging Face are scaling volatile ML models in production with versioning, retraining, and Hugging Face's Inference API to manage real-world complexity

Compare Excel and Power BI in terms of data handling, reporting, collaboration, and usability to find out which tool is better suited for decision making

Discover the best places to see the Northern Lights in 2024. Our guide covers top locations and tips for witnessing this natural spectacle