Advertisement
The terms “data science” and “machine learning” show up often, sometimes used side by side, sometimes interchangeably. At a glance, they can sound like different names for the same kind of work. They both involve large amounts of data, statistical techniques, and programming tools. But despite the overlap, they focus on different things.
Someone working in data science might never build a machine learning model, and someone building machine learning algorithms might not need to explore data in the same way a data scientist does. Understanding the split between the two fields helps clarify how they connect—and where they don’t.
Data science is a broader discipline that deals with understanding, processing, and drawing insights from data. It starts with collecting and cleaning raw data and stretches all the way to visualizing results in a way that others can act on. The goal is to answer questions and tell stories using data. This could include predicting customer churn, identifying trends in climate data, or summarizing public sentiment from social media posts.
Machine learning is narrower in scope. It’s a field that focuses on creating systems that can learn from data and make decisions or predictions without being programmed with fixed rules. The “learning” comes from feeding algorithms with examples until they pick up patterns. In practical terms, this could mean teaching a system to recognize cats in photos, translate text between languages, or detect fraudulent transactions.
In short, data science is asking questions and answering them in data. Machine learning is about creating tools to make predictions or classify data based on their experience from previous data.
Data scientists use a variety of tools. They tend to employ languages such as Python and R, along with SQL, for querying databases. Pandas, NumPy, and Matplotlib are typically used for data manipulation and visualization. Cloud platforms, dashboards, and spreadsheets can be used to deliver their results. Statistics and domain expertise are extremely important, as much of the job involves interpreting the data's implications within its context.

Machine learning engineers, while they might use the same programming languages, lean more heavily on frameworks like TensorFlow, PyTorch, Scikit-learn, and XGBoost. Their focus is on building, testing, and optimizing models. They need a strong grasp of algorithms, optimization methods, and sometimes even linear algebra and calculus. While data cleaning and processing is part of their work, it’s more of a means to an end—the model.
This is where things start to blend. Many machine learning projects begin with exploratory data analysis, a typical data science task. And many data science tasks today benefit from using machine learning to boost predictions. But the distinction lies in the intent: data science is about explaining and exploring; machine learning is about automating and predicting.
A data science workflow often begins with a problem statement. Let’s say a business wants to understand why its sales dipped last quarter. The data scientist will gather relevant data—such as sales numbers, marketing campaigns, and customer feedback—and clean it. Then, they'll explore the data, look for patterns, and build reports or dashboards that provide answers. Sometimes, they'll build predictive models, but those models serve to guide decision-making rather than act independently.
In contrast, machine learning workflows tend to be more structured around building a specific type of model. Suppose a company wants to build a spam filter. The focus then shifts to gathering labeled examples of emails, cleaning and preparing that data, selecting a model architecture, training it, testing its accuracy, and deploying it into production. Once deployed, the model may continue learning from new examples or need to be retrained over time.
The role of feedback is another difference. Data science projects may not always have clear metrics for success, especially when the work is exploratory. Machine learning projects are typically tied to measurable outcomes, such as accuracy, recall, precision, and loss values. These metrics guide improvements and help compare models objectively.
People often confuse job titles in these fields, especially since they sometimes overlap. A “data scientist” may spend most of their time in business meetings, translating company goals into analytical questions. They might use dashboards and reports to communicate findings to non-technical teams. Their day-to-day work is often a mix of statistics, data wrangling, and storytelling.

A "machine learning engineer," on the other hand, is closer to software development. They focus on the engineering side—building scalable systems that can process data in real time or handle large volumes efficiently. Their work often intersects with DevOps, cloud computing, and system design.
Some roles sit between the two. A “machine learning data scientist” might prototype models and conduct experiments, while someone in an “applied AI” role might move between both worlds—developing models and interpreting their results.
In terms of applications, data science is utilized in areas such as health analytics, market research, customer segmentation, and supply chain analysis. Machine learning is used in recommendation systems, autonomous vehicles, speech recognition, and fraud detection. The overlap is growing, but the foundation of each field remains distinct.
The line between data science and machine learning is easy to blur because they share common tools and often work together. But their core aims are different. Data science focuses on understanding data and drawing insights, while machine learning aims to build systems that learn and make predictions. Think of data science as the process of exploring and interpreting the past and present and machine learning as building tools for future automation and decision-making. Each has its strengths, and while they complement each other, they require different mindsets and skill sets. Understanding where one ends and the other begins helps make better use of both.

Compare Excel and Power BI in terms of data handling, reporting, collaboration, and usability to find out which tool is better suited for decision making

Explore the differences between the least populated countries and the most populated ones. Discover unique insights and statistics about global population distribution

Can AI bridge decades of legacy code with modern languages? Explore how IBM’s generative AI is converting COBOL into Java—and what it means for enterprise tech

How fine-tuning Llama 2 70B using PyTorch FSDP makes training large language models more efficient with fewer GPUs. A practical guide for working with massive models

How Würstchen uses a compressed latent space to deliver fast diffusion for image generation, reducing compute while keeping quality high

Discover the best places to see the Northern Lights in 2024. Our guide covers top locations and tips for witnessing this natural spectacle
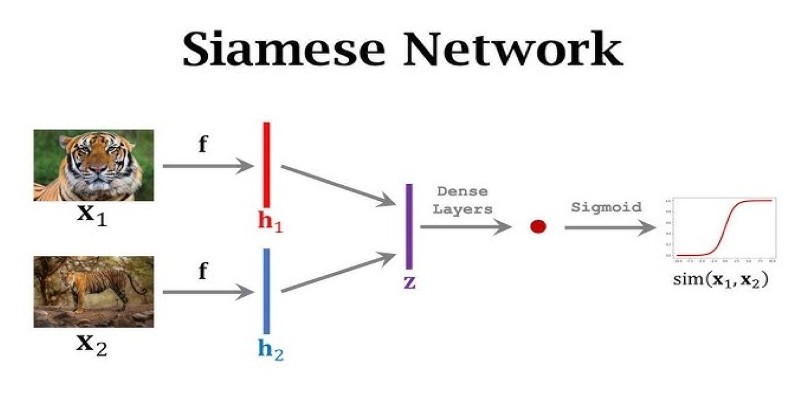
What makes Siamese networks so effective in comparison tasks? Dive into the mechanics, strengths, and real-world use cases that define this powerful neural network architecture
Explore the most unforgettable moments when influencers lost their cool lives. From epic fails to unexpected outbursts, dive into the drama of livestream mishaps

Discover five engaging and creative methods to teach your kids about saving money and instill essential financial literacy skills

How AI in food service is transforming restaurant operations, from faster kitchens to personalized ordering and better inventory management

Nvidia's Perfusion method redefines AI image personalization with efficient, non-destructive customization. Learn how this breakthrough approach enables targeted learning without model degradation

How Enterprise AI is transforming how large businesses operate by connecting data, systems, and people across departments for smarter decisions