Advertisement
Machine learning in production is rarely a smooth ride. For Rocket Money, a personal finance app that provides spending insights and subscription tracking for millions of users, the challenge isn't just building smart models—it's keeping them stable, efficient, and trustworthy in the real world. Partnering with Hugging Face gave them the infrastructure to manage this balance.
But the real story is in how they scaled volatile ML models that constantly shift under the pressure of live data, evolving usage patterns, and changing economic behavior. The collaboration turned experimentation into impact—without the usual trade-offs.
Rocket Money's ML use cases aren’t static. Their recommendation models, text classifiers, and budget forecasting tools work with live financial data that shifts quickly. Income volatility, inconsistent user behavior, and even calendar events cause ripple effects in prediction quality. These aren’t edge cases—they're expected.
Volatility in model performance doesn’t always come from poor design. Sometimes, the features just lose signal strength in production. What performs well during evaluation can degrade in weeks if a macroeconomic trend or spending habit changes. Rocket Money needed a way to not only monitor that shift but course-correct before users noticed.
Instead of relying on brittle pipelines and slow iterations, they shifted toward a Hugging Face-centric setup. This included not just using Transformers or tokenizers but integrating Hugging Face's tools for training, hosting, and versioning. The benefit? Models could be retrained and rolled out fast—without breaking anything upstream or downstream.
The usual perception of Hugging Face is a model zoo. Rocket Money used it more like a foundation. The Hub served as the central place to manage model versions, audit training changes, and run benchmarks that actually reflected production environments. Instead of moving checkpoints manually or pushing scripts through CI/CD hacks, they let the Hub manage versions, metadata, and artifacts natively.

When a model started drifting or misfiring, the team could roll back to a previous version in seconds. That sounds simple, but in most internal setups, it’s not. Hugging Face provided a mechanism to treat ML models more like apps: tracked, tested, and deployable on demand.
They also used Hugging Face’s Inference API to test inferences directly in a clean, isolated space before promoting models into Rocket Money’s stack. This decoupling from production environments gave data scientists room to experiment without worrying about breaking core user experiences.
Model performance isn’t a one-time win. Rocket Money uses feedback loops from anonymized user interactions to measure when models start failing. These aren’t just label corrections—they’re behavior signals, like whether users engage with suggestions or how long they spend on a screen.
To make that work, Rocket Money built a drift monitoring system that compared incoming data to the distribution used during training. When things skewed too far, it triggered automatic evaluations against historical baselines. This was made easier by storing all model training data and parameters in Hugging Face’s system, giving them a clean snapshot for each version.
One major advantage here was that feedback didn't need to be structured or labeled manually. Passive signals, such as click-throughs or subscription edits, were fed into the training data. Hugging Face’s datasets library let them work with mixed-type data at scale, which was essential because their inputs weren’t just text or numbers—they were timelines, nested financial entries, and metadata.
The retraining strategy was asynchronous. Instead of waiting for full retrains every month, Rocket Money ran incremental updates weekly. These models were evaluated offline with the same metrics as the live models, ensuring consistency. Then, only if they improved real-world metrics, such as engagement or accuracy, were they promoted.
The most useful outcome of Rocket Money’s partnership with Hugging Face wasn’t speed or automation—it was resilience. The ability to try, fail, roll back, and re-try without deep coordination across engineering teams made a big difference.

Volatile models no longer meant unreliable results. By isolating the model lifecycle from the core app and integrating it tightly with the Hub, the team could run more experiments without fear of regressions. The Hugging Face ecosystem worked like a pressure release valve, absorbing the complexity while giving engineers room to focus on insights rather than fire drills.
The cost was another benefit. By using Hugging Face's transformers with quantization and ONNX export features, Rocket Money reduced inference latency and compute costs—especially for models embedded in mobile or serverless environments. These weren't academic optimizations; they directly affected how often models could be refreshed and deployed.
One of the key secondary advantages of Hugging Face's platform was observability. Version tracking wasn’t just about rollback safety—it became part of debugging. Knowing exactly which tokenizer, training config, or dataset variant a model used meant that when something changed, it was traceable within minutes.
Rocket Money’s use case was financial tech, but their problems were universal. The tension between fast iteration and production stability hits every ML team eventually. What Hugging Face enabled was a clean way to separate concerns—development could move fast, and operations didn’t have to carry the risk.
Rocket Money x Hugging Face: Scaling Volatile ML Models in Production shows how structure and flexibility can coexist in live machine learning systems. Instead of fighting instability, Rocket Money built around it, using Hugging Face tools to keep models controlled, traceable, and responsive to change. Fast iteration, rollback safety, and cost-aware deployment helped turn ML from a fragile feature into a core capability. The setup allowed experimentation without risking stability and scale without losing control. By treating Hugging Face as infrastructure rather than just a model hub, Rocket Money found a sustainable way to run machine learning in production environments.

How Rocket Money x Hugging Face are scaling volatile ML models in production with versioning, retraining, and Hugging Face's Inference API to manage real-world complexity
Explore how GPTBot, OpenAI’s official web crawler, is reshaping AI model training by collecting public web data with transparency and consent in mind

How Enterprise AI is transforming how large businesses operate by connecting data, systems, and people across departments for smarter decisions
How Fetch cuts ML processing latency by 50% using Amazon Sage-Maker and Hugging Face, optimizing inference with async endpoints and Hugging Face Transformers

Explore the key differences between Frequentist vs Bayesian Statistics in data science. Learn how these two approaches impact modeling, estimation, and real-world decision-making

How Würstchen uses a compressed latent space to deliver fast diffusion for image generation, reducing compute while keeping quality high

How the ONNX model format simplifies AI model conversion, making it easier to move between frameworks and deploy across platforms with speed and consistency

How AI in food service is transforming restaurant operations, from faster kitchens to personalized ordering and better inventory management

Can AI bridge decades of legacy code with modern languages? Explore how IBM’s generative AI is converting COBOL into Java—and what it means for enterprise tech

How AI in real estate is transforming property search, pricing, and investment decisions. Learn how automation and predictive tools are streamlining the industry for buyers, agents, and investors
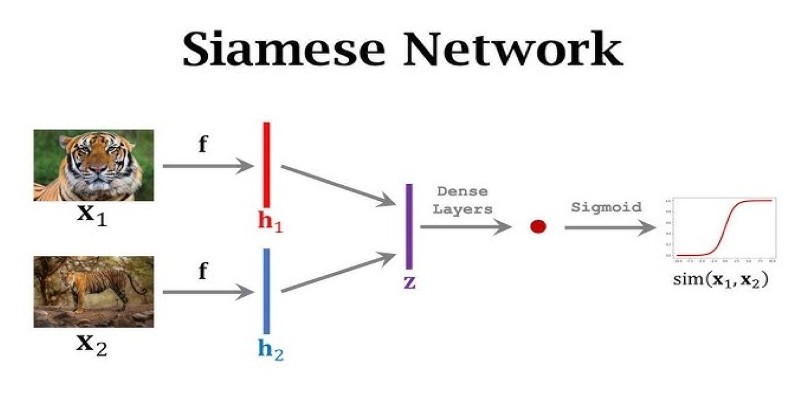
What makes Siamese networks so effective in comparison tasks? Dive into the mechanics, strengths, and real-world use cases that define this powerful neural network architecture

How GANs are revolutionizing fashion by generating high-quality design images, aiding trend forecasting, e-commerce visuals, and creative innovation in the industry