Advertisement
We're surrounded by visual content, whether we ask for it or not. From social posts to digital tools, the demand for fast and accurate images keeps growing. However, anyone who has tried to generate images from text knows the frustration. You type in something simple, like "a chair made of clouds," and wait. Then comes an image that's either too literal, too strange, or nothing like what you pictured. That's where aMUSEd stands out.
It doesn't try to overwhelm with complexity. Instead, it does one thing well: create images from text with speed and accuracy without the extra fuss. Let's take a closer look at how it works and why it feels more natural compared to other options.
Most text-to-image generators run into the same problem: too many moving parts. You enter your text, it goes through a model, and then it tries to find a balance between creativity and realism. Often, it takes several tries before you get something usable. aMUSEd approaches this differently.
At the heart of aMUSEd is a transformer model that handles both text and visual data in a way that feels direct. Instead of bouncing back and forth between different systems, it processes everything within a shared setup. This means fewer delays and less confusion between what you ask for and what you get.
One of the standout parts of aMUSEd is its size. It’s not bloated with endless parameters that make each request slow. It trims the extra bulk and keeps what matters. This makes it quicker and easier to run, even on systems without specialized hardware.
Where many models struggle is with translating abstract or creative prompts. You say, "A rainy sunset on Mars," and they give you something that looks more like a red beach. aMUSEd uses a tokenization method that treats text input with more care. It breaks it down in a way that holds onto meaning instead of just trying to match words with pixels.
What makes aMUSEd different isn’t one big trick—it’s a set of choices that work well together. Each part of the system is tuned for balance, not just performance.
While many systems use encoder-decoder models, aMUSEd sticks to a decoder-only layout. This choice cuts down on processing time. It also means that the model doesn't lose sight of earlier input while generating the image. So, if your prompt starts with "a child's drawing style," that idea stays present throughout the process.
To train the model, masked modeling plays a key role. Some parts of the input image are hidden, and the model learns to fill them in. This sharpens its ability to predict image patterns and improve output over time. It’s a more grounded approach that teaches the system to think ahead instead of just reacting.
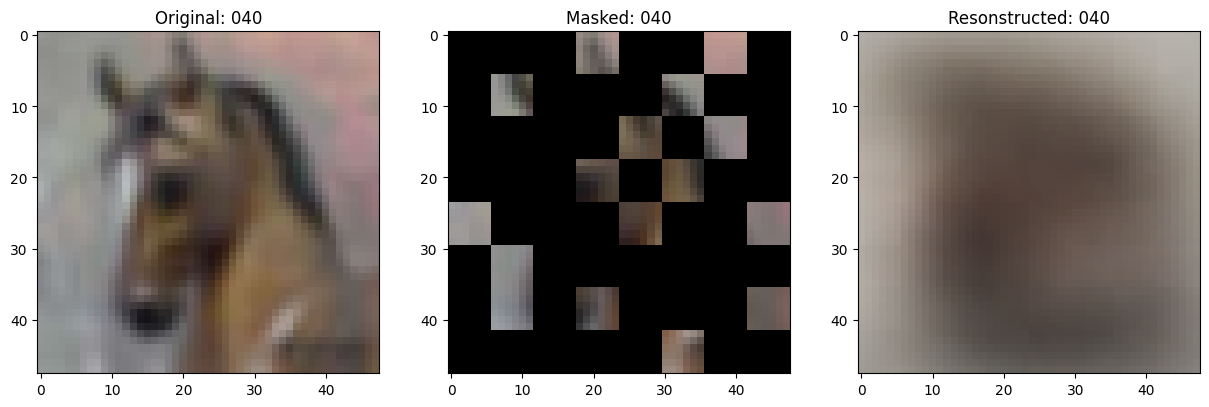
aMUSEd gives the text the spotlight early in the generation. Instead of mixing text and images from the start, it first builds a solid understanding of the prompt. Only then does it move into creating the image. This order helps reduce awkward or disjointed results.
People often give up on text-to-image tools because the results feel random. aMUSEd doesn’t try to wow you with overly stylized output unless that’s what you asked for. It sticks closer to the meaning of the prompt and avoids strange visual leaps.
When a prompt includes layered descriptions—say, “a 1920s jazz club, viewed from above”—aMUSEd does better at keeping those layers intact. It doesn’t forget the style halfway through or merge unrelated parts in odd ways. This has to do with how it maps the tokens to image concepts. There’s a tighter grip on context, and the results show it.
Fast response is not just about comfort—it affects trust. When people get slower feedback, they tend to think the system isn’t working or misinterpreting input. aMUSEd runs faster, even with detailed prompts, which builds more confidence with each use.
There’s a fine line between flexibility and control. Too many options can confuse users, especially those new to AI image generation. aMUSEd comes with defaults that are reasonable. You don’t have to tweak 10 sliders to get a usable image. And if you do want to change something, it responds without throwing everything else off.
Getting started with aMUSEd doesn’t take much setup. If you’re using the model directly or through an API, here’s a straightforward way to approach it.
Think about what you want to see. Break it into key ideas—style, setting, action. For example, “a medieval village at night, with glowing lanterns and cobblestone paths.” Try to be specific without going overboard.

Whether through code or a web interface, paste the prompt and select the image size. aMUSEd offers a range of dimensions, and the model adjusts without taking extra time.
Most prompts return in a matter of seconds. If the result isn’t quite what you expected, tweak just one part of the prompt instead of rewriting everything. Small changes tend to produce clearer differences.
Once you've got your image, download it or pass it to your next tool. aMUSEd creates files in standard formats, so there’s no need for conversion.
aMUSEd doesn't try to be everything at once. It doesn't flood you with filters or beg you to tune endless controls. It focuses on understanding your words and producing images that match. The experience feels more grounded, and the outputs are more in sync with what you had in mind. That's what makes it work. Not by being loud but by being consistent.

How the ONNX model format simplifies AI model conversion, making it easier to move between frameworks and deploy across platforms with speed and consistency

Discover the best places to see the Northern Lights in 2024. Our guide covers top locations and tips for witnessing this natural spectacle

How Würstchen uses a compressed latent space to deliver fast diffusion for image generation, reducing compute while keeping quality high

How Making LLMs Lighter with AutoGPTQ and Transformers helps reduce model size, speed up inference, and cut memory usage—all without major accuracy loss

How fine-tuning Llama 2 70B using PyTorch FSDP makes training large language models more efficient with fewer GPUs. A practical guide for working with massive models

Can AI bridge decades of legacy code with modern languages? Explore how IBM’s generative AI is converting COBOL into Java—and what it means for enterprise tech
Explore how GPTBot, OpenAI’s official web crawler, is reshaping AI model training by collecting public web data with transparency and consent in mind

How to use transformers in Python for efficient PDF summarization. Discover practical tools and methods to extract and summarize information from lengthy PDF files with ease

Explore the differences between the least populated countries and the most populated ones. Discover unique insights and statistics about global population distribution

What data management is, why it matters, the different types involved, and how the data lifecycle plays a role in keeping business information accurate and usable

Discover the top 8 most isolated places on Earth in 2024. Learn about these remote locations and their unique characteristics
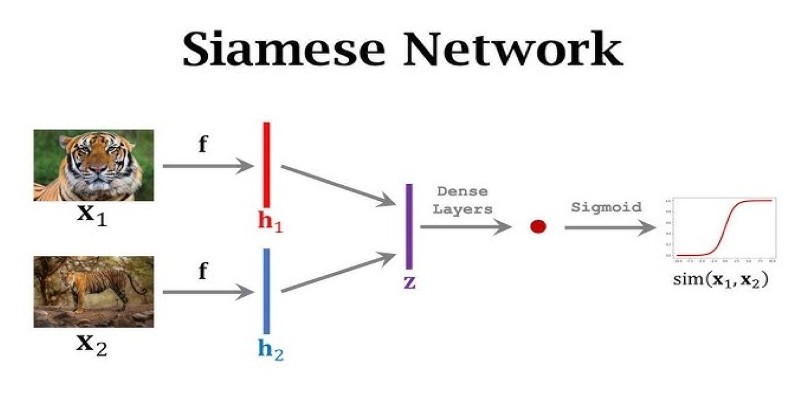
What makes Siamese networks so effective in comparison tasks? Dive into the mechanics, strengths, and real-world use cases that define this powerful neural network architecture