Advertisement
Image generation with AI has come a long way, but most models still carry the same weight: long processing times, large hardware needs, and layers of complexity. Würstchen does something different. Instead of piling on more parameters, it trims the fat. It flips the standard approach by doing most of the heavy work in a compressed space, making image creation much faster without losing visual quality.
This shift doesn’t just save time—it changes how developers can think about deploying these models. Whether you're building tools, experimenting locally, or just curious about faster generation, Würstchen offers a refreshingly practical path forward.
At its core, Würstchen is a diffusion model—but with a twist. It breaks down the process into three stages rather than doing all the heavy lifting at high resolution. Most diffusion models operate on detailed image spaces right from the start. Würstchen starts with a much smaller one, which it calls stage C. This compressed space is where the actual diffusion happens. Once a sample is generated here, it is passed through a decoder that restores it to its full image size.
This compression-first method has a real benefit: faster inference. By avoiding repeated sampling in high-dimensional pixel space, Würstchen cuts down on the time and computing needed to produce an image. The model doesn't skip steps—it just runs them in a much cleaner environment.
In practical terms, this setup leads to nearly 90% fewer operations during inference. That makes it far more efficient to run on standard GPUs or even edge devices. It also opens the door to real-time applications, where latency matters more than ever.
Würstchen isn't just a faster version of existing models—it takes a different route even during training. The model is trained in three phases. First, the stage B decoder learns to reconstruct full images from compressed representations. Next, the stage A encoder learns to map full images into this compact space. Finally, the diffusion model is trained in this compressed latent space.
This architecture lets the model specialize in small, efficient representations. The compressed space still contains enough semantic and structural detail for high-quality generation. At the same time, because it's lighter, training the diffusion model becomes faster and more memory-efficient.
The design is deliberate. Instead of relying on huge text-to-image pairs or giant batch sizes, Würstchen is tuned for stability and efficiency. That approach means better performance per GPU hour and fewer surprises when trying to scale the model.
The team behind Würstchen also released open checkpoints, which has helped researchers and developers test it out quickly. The openness around training setups, code, and samples gives it a practical edge for adoption. You can run it on consumer-grade hardware without cutting corners.
The diffusion space is crowded. There’s Stable Diffusion, Imagen, DALL·E 3, Kandinsky, and several closed models sitting behind APIs. Most of them rely on high-resolution latent or extremely large models. That makes them powerful but hard to run outside the cloud. Würstchen doesn't try to match them step by step—it offers a different kind of tradeoff.
Its focus on fast inference and small footprints makes it well-suited for experimentation, UI tools, and local apps. For developers looking to integrate generative images without massive costs or long wait times, this matters. Image quality remains competitive, especially in general prompts. In niche or hyper-detailed prompts, the larger models still have an edge, but the gap is smaller than expected.
Würstchen also fits well with existing workflows. You can feed its outputs into upscalers or pass them through refinement loops. Since the base image is already decent, these extra steps bring it closer to photo-level detail. It doesn’t try to do everything out of the box—it just does the hard part quickly and cleanly.
While most diffusion models use CLIP or T5-based text encoders, Würstchen’s pipeline is modular. That gives it flexibility. You can swap parts in and out depending on the use case. It works well with other open-source tooling, which keeps it adaptable as the landscape evolves.
The secondary keyword—fast image generation—comes into play here. Würstchen's design shows that fast image generation doesn’t have to mean low quality. The tradeoff space can be adjusted. This means developers no longer have to choose between speed and output fidelity.
Würstchen opens up new directions for diffusion-based tools. Its compact pipeline could power everything from creative coding projects to low-latency image generation in mobile apps. There’s potential for wider adoption in education, game dev, and design tools, where cost and response time matter more than raw realism.

Its structure is also interesting for the research crowd. Compressing the latent space before diffusion isn’t a new idea, but Würstchen shows how to do it in a practical, working system. This could inspire new models that work at different levels of compression or experiment with alternative representations like tokens or graphs.
There's growing interest in diffusion models that can generate faster without burning through computing. Würstchen sets a strong example here. As GPUs get more expensive and energy use comes under the microscope, models like this may become more relevant than ever.
The secondary keyword appears again here—fast image generation at scale is possible with the right structure. Würstchen shows that with smart choices, models don’t have to grow bigger to improve.
For those looking to build on it, the code and weights are on Hugging Face. That helps people quickly test variations or train similar pipelines for other domains, like medical or satellite imagery. Since the core idea isn’t tied to any one kind of image, it can be applied more broadly.
Würstchen takes a different path in image generation by moving the heavy work into a compressed latent space. This shift speeds up diffusion without losing much quality, making the process cheaper and easier to run. It’s not trying to beat the biggest models, but it shows that fast image generation is possible without major compromises. For many use cases, smart design beats raw size—and Würstchen delivers on that idea.

Explore the range of quantization schemes natively supported in Hugging Face Transformers and how they improve model speed and efficiency across backends like Optimum Intel, ONNX, and PyTorch

Explore the key differences between Frequentist vs Bayesian Statistics in data science. Learn how these two approaches impact modeling, estimation, and real-world decision-making

How fine-tuning Llama 2 70B using PyTorch FSDP makes training large language models more efficient with fewer GPUs. A practical guide for working with massive models

Discover the best places to see the Northern Lights in 2024. Our guide covers top locations and tips for witnessing this natural spectacle

Can AI bridge decades of legacy code with modern languages? Explore how IBM’s generative AI is converting COBOL into Java—and what it means for enterprise tech

How Würstchen uses a compressed latent space to deliver fast diffusion for image generation, reducing compute while keeping quality high

How the ONNX model format simplifies AI model conversion, making it easier to move between frameworks and deploy across platforms with speed and consistency
Explore the most unforgettable moments when influencers lost their cool lives. From epic fails to unexpected outbursts, dive into the drama of livestream mishaps
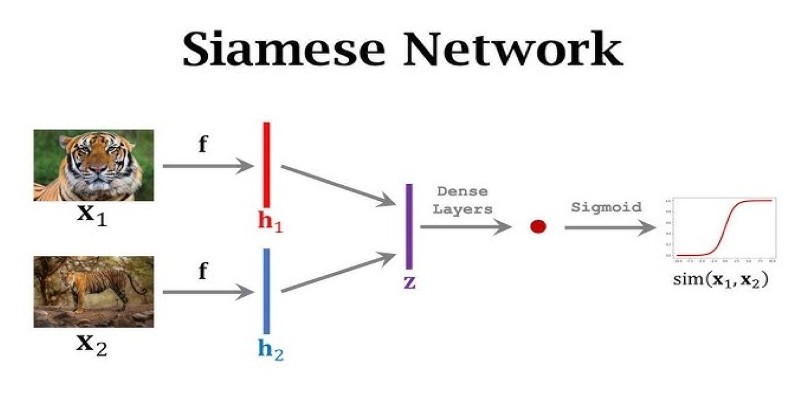
What makes Siamese networks so effective in comparison tasks? Dive into the mechanics, strengths, and real-world use cases that define this powerful neural network architecture

Discover the top ten tallest waterfalls in the world, each offering unique natural beauty and immense height

What data management is, why it matters, the different types involved, and how the data lifecycle plays a role in keeping business information accurate and usable

How GANs are revolutionizing fashion by generating high-quality design images, aiding trend forecasting, e-commerce visuals, and creative innovation in the industry